- October 5, 2020
- Posted by: administrator
- Category: MicroSoft
A preliminary report by Microsoft states that a bug in the deployment of an Azure AD service update caused Monday’s Office 365 outage.
Starting at 5:20 PM EST on September 28th, people worldwide were unable to login to Office 365 and other related services, including Microsoft Teams, Office.com, Power Platform, and Dynamics365.
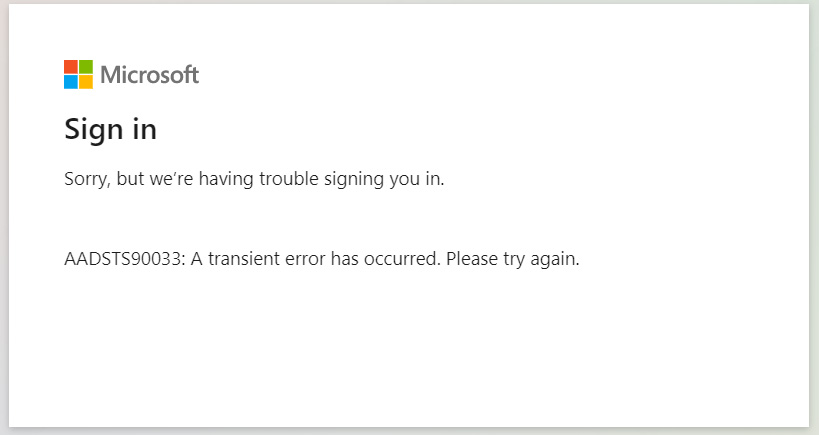
When attempting to do so, people were greeted with a “AADSTS90033: A transient error has occurred. Please try again” error message.
For those who were already logged into these services, they were largely unaffected by the outage.
Service update mistakenly hits the production environment
According to a preliminary post-incident report from Microsoft, a service update for Azure AD mistakenly hit the production environment and caused service availability to degrade.
When deploying service updates, Microsoft first tests them in five different “rings” before the update makes it to the production environment. This procedure allows Microsoft to test an update on inner rings with little data before they hit production rings used by its customers.
A bug in Microsoft’s Safe Deployment Process (SDP) caused a service update to be deployed to all rings simultaneously rather than first being deployed to the test ring.
“Azure AD is designed to be a geo-distributed service deployed in an active-active configuration with multiple partitions across multiple data centers around the world, built with isolation boundaries. Normally, changes initially target a validation ring that contains no customer data, followed by an inner ring that contains Microsoft only users, and lastly our production environment. These changes are deployed in phases across five rings over several days.”
“In this case, the SDP system failed to correctly target the validation test ring due to a latent defect that impacted the system’s ability to interpret deployment metadata. Consequently, all rings were targeted concurrently. The incorrect deployment caused service availability to degrade,” Microsoft explained in their preliminary post incident report.
After learning of the issues, Microsoft tried to perform an automated rollback of the change, but a bug in their Safe Deployment Process (SDP) corrupted metadata and required a much longer manual rollback.
“Within minutes of impact, we took steps to revert the change using automated rollback systems which would normally have limited the duration and severity of impact. However, the latent defect in our SDP system had corrupted the deployment metadata, and we had to resort to manual rollback processes. This significantly extended the time to mitigate the issue,” Microsoft explained.
During this outage, Microsoft said that the Americas and Asia-Pacific regions suffered the most problems when logging into services.
A final report from Microsoft should become available by the end-of-day on October 3rd.
NOTE:: This article is copyright by bleepingcomputer.com and we are using it for educational or Information purpose only